






NVIDIA pushes AI factories from concept to deployment
NVIDIA links Vera Rubin, Dynamo and DSX into a broader AI factory system built around efficiency, simulation and agentic workloads.

NVIDIA has expanded its AI infrastructure push beyond chips and servers, laying out a broader system for how large-scale AI facilities should be designed, built and operated. The company’s announcements at GTC on 16 March centred on a new DSX AI Factory reference design, a digital twin blueprint in Omniverse, and a wider rack-scale platform built around Vera Rubin, Dynamo, Vera CPU and BlueField-4 STX.
Table Of Content
Taken together, the announcements point to a more integrated view of AI infrastructure. Rather than treating compute, storage, networking, power and cooling as separate layers, NVIDIA is presenting them as a single production system designed to maximise tokens per watt, reduce deployment delays and keep utilisation high under training, inference and agentic workloads.
That framing reflects a broader shift in the market. As AI systems move from model development into large-scale deployment, the infrastructure challenge is no longer limited to adding more GPUs. It now includes how clusters are planned, simulated, provisioned, cooled, connected to the grid and tuned for sustained inference performance.
AI factories move from hardware stack to operating model
The centrepiece of NVIDIA’s latest infrastructure push is the Vera Rubin DSX AI Factory reference design. The company describes it as a guide for building codesigned AI infrastructure, covering compute, Spectrum-X Ethernet networking and storage, alongside best practices for power, cooling and control systems.

That reference design is paired with the Omniverse DSX Blueprint, which is now generally available and fully compatible with Vera Rubin DSX. NVIDIA says the blueprint allows developers and operators to build physically accurate digital twins of AI factories, simulate operations in real time and evaluate layouts, thermal behaviour, power topologies and operational policies before construction or deployment begins.
The company argues that this approach addresses a growing practical problem. Building large-scale AI factories for training and inference requires close coordination across infrastructure, power, cooling, networking, software and compute, and traditional design methods struggle to model the entire system before hardware is installed.
Jensen Huang, founder and CEO of NVIDIA, said, “In the age of AI, intelligence tokens are the new currency, and AI factories are the infrastructure that generates them.” He added, “With the NVIDIA Vera Rubin DSX AI Factory reference design and Omniverse DSX Blueprint, we are providing the foundation to build the world’s most productive AI factories, accelerating time to first revenue and maximizing scale and energy efficiency.”
The DSX software stack is intended to support that goal through a set of modular components. DSX Max-Q is designed to maximise computing output and token performance per watt within a fixed power budget, while DSX Flex links AI factories to power-grid services so they can adjust usage dynamically and coordinate with onsite generation.
NVIDIA is also positioning DSX Exchange as a way to connect compute, network, energy, power and cooling signals across IT and operational systems. DSX Sim and DSX SimReady extend that into simulation, using DSX Air to model GPUs, networking and partner infrastructure and to connect 3D geometry, logistics and system behaviour into a higher-fidelity digital twin.
Vera Rubin extends the system-level push
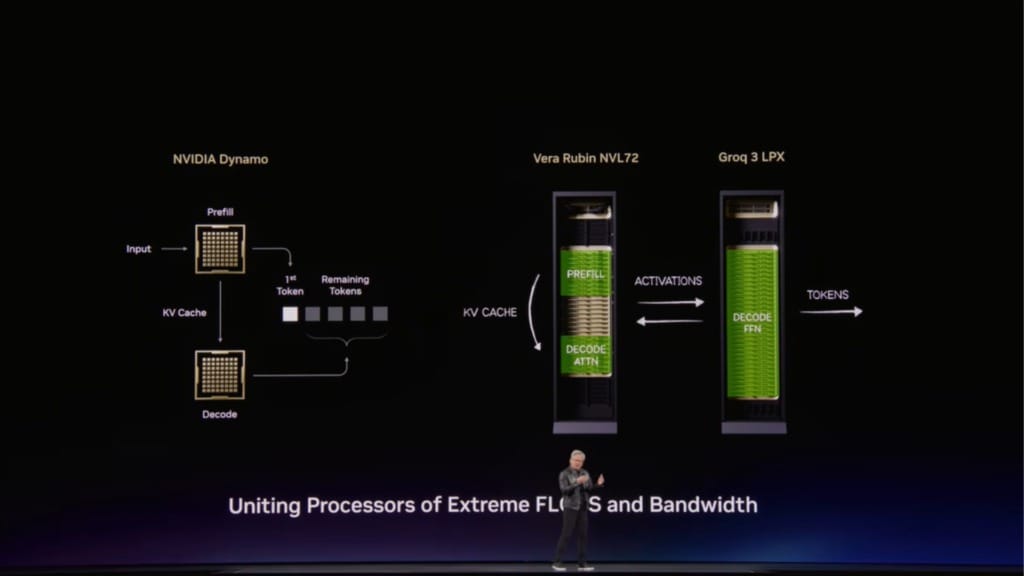
The reference design sits alongside the wider Vera Rubin platform, which NVIDIA says is now in full production. The platform combines the Vera CPU, Rubin GPU, NVLink 6 Switch, ConnectX-9 SuperNIC, BlueField-4 DPU, Spectrum-6 Ethernet switch and the newly integrated Groq 3 LPU into what NVIDIA describes as a single AI supercomputer for every phase of AI.

That matters because the company is no longer presenting infrastructure as a collection of discrete components. The Vera Rubin platform is organised around racks and pod-scale systems, including Vera Rubin NVL72 GPU racks, Vera CPU racks, Groq 3 LPX inference accelerator racks, BlueField-4 STX storage racks and Spectrum-6 SPX Ethernet racks.
NVIDIA says the NVL72 rack integrates 72 Rubin GPUs and 36 Vera CPUs connected by NVLink 6, alongside ConnectX-9 SuperNICs and BlueField-4 DPUs. The company claims the system can train large mixture-of-experts models with one-fourth the number of GPUs compared with the Blackwell platform, while achieving up to 10x higher inference throughput per watt at one-tenth the cost per token.
The company is also tying Vera Rubin directly to a broader deployment model. It says the platform scales with Quantum-X800 InfiniBand and Spectrum-X Ethernet for hyperscale AI factories, with an ecosystem of more than 80 NVIDIA MGX ecosystem partners and a global supply chain supporting what it calls its most extensive pod-scale platform to date.
Huang said, “Vera Rubin is a generational leap — seven breakthrough chips, five racks, one giant supercomputer — built to power every phase of AI.” He added that “the agentic AI inflection point has arrived with Vera Rubin kicking off the greatest infrastructure buildout in history.”
Support from major AI labs and cloud providers also signals where NVIDIA expects the platform to land first. The company said Vera Rubin-based products will be available from partners in the second half of this year, including Amazon Web Services, Google Cloud, Microsoft Azure, Oracle Cloud Infrastructure and NVIDIA Cloud Partners such as CoreWeave, Crusoe, Lambda, Nebius, Nscale and Together AI.
Inference software becomes infrastructure control layer
If Vera Rubin is the physical backbone of NVIDIA’s AI factory strategy, Dynamo is being positioned as the control layer for inference at scale. NVIDIA announced Dynamo 1.0 as open source software for generative and agentic inference, describing it as the distributed operating system of AI factories.
The company says Dynamo coordinates GPU and memory resources across the cluster, helping AI systems handle bursts of requests with different sizes, modalities and performance requirements. That is increasingly important as agentic AI moves into production, where infrastructure has to manage not just one-off prompts but sequences of reasoning, tool use and retrieval over longer interactions.
According to NVIDIA, Dynamo 1.0 can split inference work across GPUs, move data between GPUs and lower-cost storage, and route requests to GPUs that already hold the most relevant short-term memory from earlier steps. When that memory is no longer needed, the system can offload it to ease memory pressure and reduce wasted work.
The company says recent industry benchmarks showed Dynamo boosting inference performance of Blackwell GPUs by up to 7x. NVIDIA argues that this lowers token cost and increases revenue opportunity for millions of GPUs through free, open source software rather than new hardware alone.
That software-first performance layer is also being tied to the broader open source ecosystem. NVIDIA said Dynamo and TensorRT-LLM optimisations integrate with frameworks such as LangChain, llm-d, LMCache, SGLang and vLLM, while core components including KVBM, NIXL and Grove are available as standalone modules.
Adoption claims stretch across cloud, AI-native and enterprise customers. NVIDIA said the inference platform is supported by Amazon Web Services, Microsoft Azure, Google Cloud and OCI, as well as cloud partners such as Alibaba Cloud, CoreWeave, Together AI and Nebius, and enterprises including ByteDance, Meituan, PayPal and Pinterest.
CPU and storage are being redesigned for agentic workloads
NVIDIA’s announcements also show how much of the agentic AI narrative now depends on infrastructure outside the GPU. The company introduced Vera CPU as a processor built for data processing, AI training and agentic inference at scale, arguing that reasoning and agentic workloads are increasingly driven by the systems supporting models that plan tasks, run tools, interact with data, execute code and validate results.
Vera features 88 custom NVIDIA-designed Olympus cores and uses LPDDR5X memory, which the company says delivers up to 1.2 TB/s of bandwidth. NVIDIA claims Vera provides results twice as efficiently and 50% faster than traditional rack-scale CPUs, and says a new rack design can integrate 256 liquid-cooled Vera CPUs to sustain more than 22,500 concurrent CPU environments.
That CPU layer is paired with new storage architecture built for long-context reasoning. NVIDIA introduced BlueField-4 STX as a modular reference architecture for accelerated storage infrastructure, aimed at keeping data close and accessible for agentic AI factories so they can maintain throughput and responsiveness across inference, training and analytics.
The first rack-scale implementation includes the CMX context memory storage platform, which NVIDIA says expands GPU memory with a high-performance context layer for scalable inference and agentic systems. The company claims this can provide up to 5x tokens per second compared with traditional storage, while STX as a whole can deliver 4x higher energy efficiency and ingest 2x more pages per second for enterprise AI data.
Mistral AI cofounder and chief technology officer Timothée Lacroix said, “The NVIDIA BlueField-4 STX rack-scale context memory storage system will enable a critical performance boost needed to exponentially scale our agentic AI efforts.” He added that the system is “ideally positioned to ensure that our models can maintain coherence and speed when reasoning across massive datasets.”
Simulation and utilities become part of the deployment equation
The DSX strategy also extends beyond IT infrastructure into energy and construction. NVIDIA said energy is now the biggest bottleneck for AI infrastructure buildouts, citing more than US$300 billion in equipment backlogs and over 200 gigawatts of projects waiting in US interconnection queues.
That is one reason the company is linking DSX to power-grid management and digital infrastructure planning. Emerald AI is integrating DSX Flex with its Conductor platform for real-time power control, while GE Vernova, Hitachi and Siemens Energy are working with NVIDIA around grid modelling, planning and monitoring.
A broader industrial ecosystem is also being pulled into the stack. NVIDIA said Cadence, Dassault Systèmes, Eaton, Jacobs, Nscale, Phaidra, Procore, PTC, Schneider Electric, Siemens, Switch, Trane Technologies and Vertiv are contributing to the DSX architecture and blueprint through platform integration, SimReady assets and software connections.
That support ranges from simulation and product lifecycle management to prefabricated infrastructure and thermal optimisation. Phaidra, for example, has integrated DSX Max-Q into a self-learning AI agent that NVIDIA says can deliver about 10% more compute by reducing cooling spikes while maintaining safety and freeing up power for token production.
DSX Air is being presented as a practical deployment tool inside that broader system. NVIDIA says the platform lets customers and partners construct a full digital twin of an AI factory before hardware arrives, validate networking, storage, orchestration and security, and reduce time to first token from weeks or months to days or hours.
CoreWeave is already using DSX Air to build and test digital twins of AI factories in the cloud, while Siam.AI and Hydra Host are using it to validate architectures and orchestration workflows before physical deployment. That shifts simulation from design aid to operational requirement, especially as AI factories grow in size, cost and complexity.




